古典的条件づけとオペラント条件づけの簡単な説明

目次
心理学を学ぶ学生、教師、専門家を含め、多くの人が古典的条件づけとオペラント条件づけの概念を分かりにくいと感じている。 そこで私は、古典的条件づけとオペラント条件づけのプロセスを簡単に説明することにした。 あなたがこれから読むものほど簡単なものはないだろう。
古典的条件づけとオペラント条件づけは、人間や他の動物がどのように学習するかを説明する2つの基本的な心理学的プロセスである。 この2つの学習様式の根底にある基本的な概念は次のとおりである。 協会 .
簡単に言えば、私たちの脳は連想マシーンであり、物事を互いに関連付けることで、私たちの世界について学び、より良い判断を下すことができるのだ。
もし私たちがこの基本的な関連付けの能力を持っていなかったら、世の中で正常に機能し、生き残ることはできなかっただろう。 関連付けによって、私たちは最小限の情報に基づいて素早い決断を下すことができる。
例えば、うっかり熱いストーブに触れてしまったとき、痛みを感じてとっさに腕を引く。 そうすると、「熱いストーブに触るのは危険だ」と学習する。 この学習能力があるため、「熱いストーブ」と「痛み」を結びつけて、今後はこの行動を避けようと努力する。
もし、そのような連想(熱いストーブ=痛み)が形成されていなかったら、おそらくまた熱いストーブに触れ、手を火傷する危険性を高めていただろう。
古典的条件づけとオペラント条件づけは、このような結びつきを形成する2つの方法である。
古典的条件づけとは何か?
古典的条件付けは、イワン・パブロフが唾液を分泌する犬を対象に行った有名な実験で科学的に実証された。 彼は、犬が食べ物を提示されたときだけでなく、食べ物を提示する直前にベルが鳴ったときにも唾液を分泌することに気づいた。
どうしてそうなるんだ?
食べ物を見たり匂いを嗅いだりすることで唾液が分泌されるのは理にかなっている。 私たちもそうだが、犬がベルの音を聞いて唾液が分泌されるのはなぜだろう?
その結果、犬たちはベルを鳴らす音と食べ物を結びつけていたことが判明した。 犬たちが「食べ物」と「ベルを鳴らす音」を結びつけるには、十分な回数が必要だったのだ。
パブロフは実験において、食べ物を提示し、同時にベルを何度も鳴らすと、食べ物が提示されていなくても、ベルが鳴ると犬は唾液を分泌することを発見した。
つまり、犬はベルを聞くと唾液が出るように「条件付け」されたのである。 後天的 条件反射である。
用語に慣れるために、すべてを最初から説明しよう。
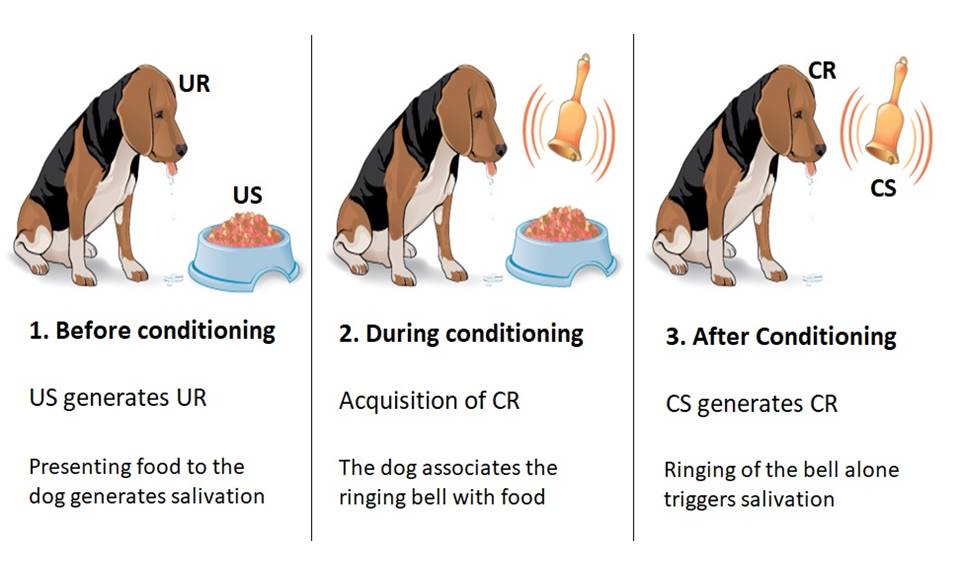
コンディショニング前
当初、犬は食べ物を提示されると唾液を分泌した。 これは食べ物を提示することで生じる通常の反応である。 無条件刺激 (唾液分泌は 無条件反応 (UR)。
もちろん、"無条件 "という言葉を使うということは、連想や条件付けがまだ行われていないということだ。
まだコンディショニングが行われていないので、ベルを鳴らすことは 中立刺激 (NS)は、今のところ犬に何の反応も示さないからだ。
コンディショニング中
中立刺激(ベルの音)と無条件刺激(食べ物)を一緒に繰り返し犬に提示すると、犬の頭の中で対になる。
それほどまでに、中立刺激(ベルの音)だけで、無条件刺激(食物)と同じ効果(唾液分泌)が得られるのである。
条件づけが起こると、ベルの音(以前はNS)が条件刺激(CS)となり、唾液分泌(以前はUR)が条件反応(CR)となる。
食べ物(US)と鳴り響くベル(NS)が対になる最初の段階をこう呼ぶ。 取得 なぜなら、犬は新しい反応(CR)を獲得する過程にあるからだ。
コンディショニング後
条件付け後、ベルの音だけで唾液分泌が誘発されるが、時間の経過とともに、ベルの音と食べ物がペアでなくなるため、この反応は減少する傾向がある。
言い換えれば、ペアリングはますます弱くなる。 絶滅 条件反応の
ベルを鳴らしても、それ自体が唾液分泌を誘発することはなく、唾液分泌を自然に自動的に誘発する食べ物と組み合わせない限り、唾液分泌を誘発することはできない。
要するに、ペアリングによって、中性刺激は無条件反応を引き起こす無条件刺激の能力を一時的に「借りる」ことができるのである。
条件反射が消失した後、しばらく間を置くと再び出現することがある。 これを「条件反射」と呼ぶ。 自然回復 .
古典的条件づけの例をもっと。 一般化と差別
古典的条件づけにおいて、刺激汎化とは、生物が以下のような刺激にさらされたときに、条件反応を引き起こす傾向のことである。 同じような 条件刺激に対する
つまり、パブロフの犬は、特定のベルの音を聞くと唾液を分泌するように条件付けされていたにもかかわらず、他の似た音のするものに対しても唾液を分泌してしまうのである。
パブロフの犬が条件づけの後、鳴り響く火災報知器や自転車の車輪の音、あるいはガラス板を叩く音にさらされると唾液を出すようになったとしたら、これは汎化の一例である。
要するに、犬の心はこれらの異なる刺激を同じものとして認識し、同じ条件反応を引き起こすのである。
例えば、初対面の他人と接するときに不快感を覚えるのは、その人の顔立ちや歩き方、声や話し方が、過去に嫌いだった人を思い出させるからかもしれない。
パブロフの犬が、これらの一般化された刺激と環境中の他の無関係な刺激とを区別する能力は、次のように呼ばれている。 差別 したがって、一般化されていない刺激は、他のすべての刺激から識別される。
恐怖症と古典的条件づけ
恐怖や恐怖症を条件づけられた反応と考えれば、古典的条件づけの原理を応用して、これらの反応を絶滅させることができる。
たとえば、人前で話すことを恐れる人は、人前で話すことになったとき、最初に何度か嫌な経験をしたことがあるかもしれない。
彼らが感じた恐怖や不快感と、「話すために立ち上がる」という行動が対になり、今では「話すために立ち上がる」という発想だけで恐怖反応が起こるようになった。
もしこの人が、最初の恐怖にもかかわらず、もっと頻繁に話すようになれば、やがて「人前で話すこと」と「恐怖反応」は解きほぐされるだろう。 恐怖反応は消滅するだろう。
これには2つの方法がある。
まず、恐怖が薄れ、やがて消えるまで、その人を恐怖の状況にさらし続ける。 これを「恐怖」と呼ぶ。 フラッディング 一度限りのイベントである。
あるいは、次のような方法もある。 系統的脱感作 長期間にわたって、さまざまな恐怖の度合いに徐々にさらされる。
古典的条件づけの限界
古典的条件付けは、何にでも何でも組み合わせられると思わせるかもしれない。 実際、これはこの分野で活躍する理論家たちの初期の仮定の一つだった。 彼らはこれをこう呼んだ。 等価性 しかし、ある種の刺激はある種の刺激と対になりやすいことが後に知られるようになった1。
言い換えれば、どんな刺激でも他の刺激と組み合わせられるわけではないのだ。 私たちは、ある種の刺激に対して他の刺激よりも反応を起こすように「生物学的に準備」されているのだろう2。
たとえば、私たちの多くはクモを恐れるが、糸の束を見てクモと勘違いすると、この恐怖反応が引き起こされることがある(一般化)。
このような一般化は、無生物にはほとんど起こらない。 進化論的な説明では、私たちの祖先は無生物よりも有生物(捕食者、クモ、ヘビ)を恐れる理由が多かったとされている。
つまり、ロープをヘビと見間違えることはあっても、ヘビをロープと見間違えることはほとんどないということだ。
オペラント条件づけ
古典的条件づけが、私たちが出来事をどのように関連づけるかについて語るのに対し、オペラント条件づけは、私たちが自分の行動をどのようにその結果と関連づけるかについて語る。
オペラント条件づけは、純粋にその結果に基づいて、ある行動を繰り返す可能性を教えてくれる。
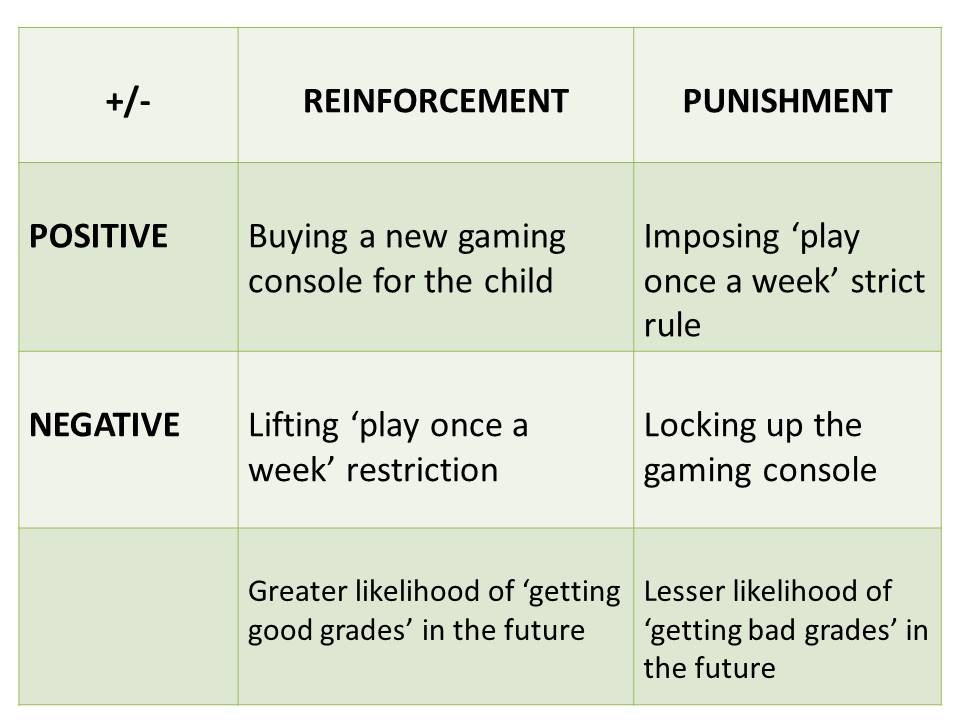
あなたの行動が将来起こりやすくなるような結果は、次のように呼ばれる。 リインフォースメント そして、その行動が将来起こりにくくなるような結果をこう呼ぶ。 懲罰 .
例えば、子供が学校で良い成績を取り、親がご褒美としてお気に入りのゲーム機を買ってあげたとする。
それは、ゲーム機が、特定の行動(良い成績を取ること)をより多く将来起こすことを促す強化剤になっているからだ。
望ましいものがあるとき 所定 ある行動をした人が、将来その行動をする可能性を高めるために、その行動をすることを「行動」と呼ぶ。 正の強化 .
つまり、上記の例では、ゲーム機は正の強化子であり、それを子供に与えることは正の強化である。
しかし、特定の行動の頻度を将来的に増加させることができる唯一の方法は、正の強化ではありません。 親が子供の「良い成績を取る」行動を強化することができる別の方法があります。
もし子供が将来のテストで良い結果を出すと約束すれば、親は厳しくなくなり、以前課せられていた制限をいくつか解除するかもしれない。
このような好ましくないルールのひとつに、「ビデオゲームは週に1回」というものがある。 親はこのルールをなくし、週に2回か3回ビデオゲームをしてもいいと子供に言うかもしれない。
その代わり、子供は学校で良い成績を取り続けなければならない。
このタイプの強化は、望ましくないもの(厳格なルール)が さらわれた と呼ばれる。 負の強化 .
ポジティブ」とは、常に何かを意味する。 所定 否定的」とは、常に何かを意味する。 さらわれた 彼らから
上記の正の強化も負の強化も、強化の最終目標は同じであることに注意してください。
もちろん、行動の実行者は望ましいものを得たいし、望ましくないものを取り除きたい。
このどちらか、あるいは両方の好意を相手に向けることで、相手があなたに従い、あなたが将来繰り返してほしい行動を繰り返す可能性が高くなる。
ここまで、強化がどのように機能するかについて述べてきた。 行動がもたらす結果について考えるには、もう一つの方法がある。
処罰
ある行動の結果が、その行動を 少ない 将来発生する可能性のある結果は、次のように呼ばれる。 懲罰 つまり、強化は将来の行動の可能性を高め、罰はその可能性を低下させる。
上の例の続きだが、例えば1年後くらいに、その子がテストの成績が悪くなり、調子に乗って勉強よりもテレビゲームに時間を割くようになったとする。
さて、この行動(悪い成績を取ること)は、親が将来的に減らしてほしいものである。 将来的にこの行動の頻度を減らしたいのである。 だから罰を使わなければならない。
ここでも親は、子供が自分の行動(悪い成績を取ること)を減らすよう動機付けるために、何かを与える(+)か、何かを取り上げる(-)かによって、罰を二通りに使い分けることができる。
この時、親は子供の行動を阻止しようとするので、子供に好ましくないものを与えたり、子供にとって好ましいものを取り除いたりしなければならない。
もし、親が子供に厳しいルールを再び課すなら、彼らは次のようになる。 供与 だからこれは、彼が望ましくないと思うものだ。 正罰 .
もし親が子供のゲーム機を取り上げて小屋に閉じ込めれば、親は次のようになる。 奪取 これは否定的な罰である。
どのような強化や罰が実行されているかを覚えておくには、常に行動の実行者を念頭に置いてください。 強化や罰をそれぞれ使って増やしたり減らしたりしたいのは、その人の行動なのです。
また、行動の実行者が何を欲しているかを念頭に置いておく。 そうすることで、何かを与えたり取り上げたりすることが強化なのか罰なのかを見分けることができる。
逐次近似とシェーピング
犬やその他の動物が、主人の命令に従って複雑な芸をするのを見たことがあるだろうか? それらの動物はオペラント条件付けを使って訓練されている。
犬がジャンプ(行動)した後、おやつ(正の強化)をもらえば、障害物を飛び越えさせることができます。 これは簡単なトリックです。 犬はあなたの命令でジャンプする方法を学んでいます。
犬が望む複雑な行動に近づいていくまで、より多くのご褒美を与えることで、このプロセスを続けることができます。 これを「ご褒美」と呼びます。 逐次近似 .
犬がジャンプした直後にスプリントをさせたいとします。 犬がジャンプしたらご褒美をあげ、スプリントしたらご褒美をあげなければなりません。 最終的には、最初のご褒美(ジャンプの後)を捨て、犬がジャンプ+スプリントの一連の行動をしたときだけご褒美をあげればよいのです。
関連項目: 作り笑顔と本物の笑顔このプロセスを繰り返すことで、犬にジャンプ+疾走+走などを一度に訓練することができる。 このプロセスをこう呼ぶ。 シェーピング .3
このビデオはシベリアンハスキーの複雑な行動の形成を示しています:
補強スケジュール
オペラント条件づけでは、強化は反応の強さを増す(将来起こりやすくなる)。 強化の与え方(強化スケジュール)は反応の強さに影響する4。
ある行動が起こるたびにその行動を強化する(連続強化)こともできるし、あるときだけ強化する(部分強化)こともできる。
関連項目: 女性を見つめる心理部分強化には時間がかかるが、発達した反応は消滅にかなり強い。
子供が試験で良い点を取るたびにキャンディーを与えるのは、継続的強化である。 一方、良い点を取るたびにではなく、何回かに分けてキャンディーを与えるのは、部分強化である。
部分的または断続的な強化スケジュールは、いつ強化するかによって異なるタイプがあります。
ある行動が一定回数行われた後に強化剤を与えることを、次のように呼ぶ。 固定比率 .
例えば、子供が3つの試験で良い点を取るたびにキャンディーを与え、3つの試験で良い点を取ったらまたご褒美を与える、といった具合である(行動を行う回数は決まっている=3回)。
一定の間隔をおいて補強が行われる場合、それは「補強」と呼ばれる。 固定インターバル 補強スケジュール
例えば、毎週日曜日にキャンディを与えるというのは、固定間隔強化スケジュール(固定時間間隔=7日間)である。
これらは固定強化スケジュールの例であった。 強化スケジュールは変動することもある。
ある行動が予測不可能な回数繰り返された後に強化が与えられる場合、次のように呼ばれる。 可変比率 補強スケジュール
例えば、2回、4回、7回、9回と良い点数を取ったらキャンディーを与える。 2回、4回、7回、9回は乱数であり、固定比率強化スケジュール(3回、3回、3回...)のように一定のギャップの後に発生するわけではないことに注意。
強化が予測不可能な間隔の後に与えられる場合、次のように呼ばれる。 可変インターバル 補強スケジュール
例えば、2日後にキャンディーを与え、3日後に与え、1日後に与えるといった具合である。 固定間隔強化スケジュール(7日間)のように、一定の時間間隔があるわけではない。

一般に、変動強化は固定強化よりも強い反応を引き起こす。 これは、報酬を得ることに対する固定的な期待がないため、いつでも報酬を得られるかもしれないと思わせるためであろう。 これは非常に中毒性が高い可能性がある。
ソーシャルメディアの通知は、可変強化の良い例です。 いつ(可変間隔)、何回(可変比率)チェックしたら通知(強化)が来るかわかりません。
そのため、通知が来ることを期待してアカウントをチェックし続ける(行動を強化する)可能性が高い。
参考文献
- Öhman、A., Fredrikson、M., Hugdahl、K., & Rimmö、P. A. (1976). ヒトの古典的条件付けにおける等位性の前提:潜在的恐怖刺激に対する条件付けされた皮膚電気反応。 実験心理学雑誌:一般 , 105 (4), 313.
- McNally, R. J. (2016). セリグマンの「恐怖症と覚悟」(1971)の遺産。 行動療法 , 47 (5), 585-594.
- ピーターソン、G.B.(2004)。 偉大な照明の日:BFスキナーのシェーピングの発見。 行動実験分析学雑誌 , 82 (3), 317-328.
- Ferster, C. B., & Skinner, B. F. (1957). Schedules of reinforcement.